
先日プロバイダ責任制限法の改正案が閣議決定されました。WEBサービス企業に勤める私にとって、2020年から続くネット上誹謗中傷などの違法情報発信者に関する発信者情報開示手続きの見直しに引き続き目が離せません。
過去にプロバイダ責任制限法について、エンジニアである私の知見を交えて対応方法の記事を書きました。
しかしながら、これはあくまで一般論で、現実的な運用では完全対応はとても難しいという見解を持っています。この記事ではその難しさ・課題・危機感について述べたいと思います。
目次
知識のおさらい
具体的な課題を述べる前に、プロバイダ責任制限法と最低限抑えたい技術知識をおさらいしたいと思います。おさらいするにあたって適時過去に私が書いた記事もご紹介するので見直していただけますと幸いです。
プロバイダ責任制限法とは
名誉毀損表現、著作権法違反など、違法情報が投稿された時に、その投稿を削除を施したり、被害を受けた方から投稿者情報の開示を求められた時に開示することに関しての規定を定めたものです。
投稿者情報として開示可能な項目については省令で以下8項目が定められております。
- 氏名・または名称
- 住所
- 電話番号
- 電子メールアドレス
- 投稿時のアクセス元のIPアドレスとポート番号
- 携帯端末識別符号
- SIMカード識別符号
- 投稿時のタイムスタンプ
本人確認が厳格な会員サービスを除くと、WEBサービスにとって重要なのはタイムスタンプと投稿時のアクセス元のIPアドレスとポート番号の開示がポイントになります。
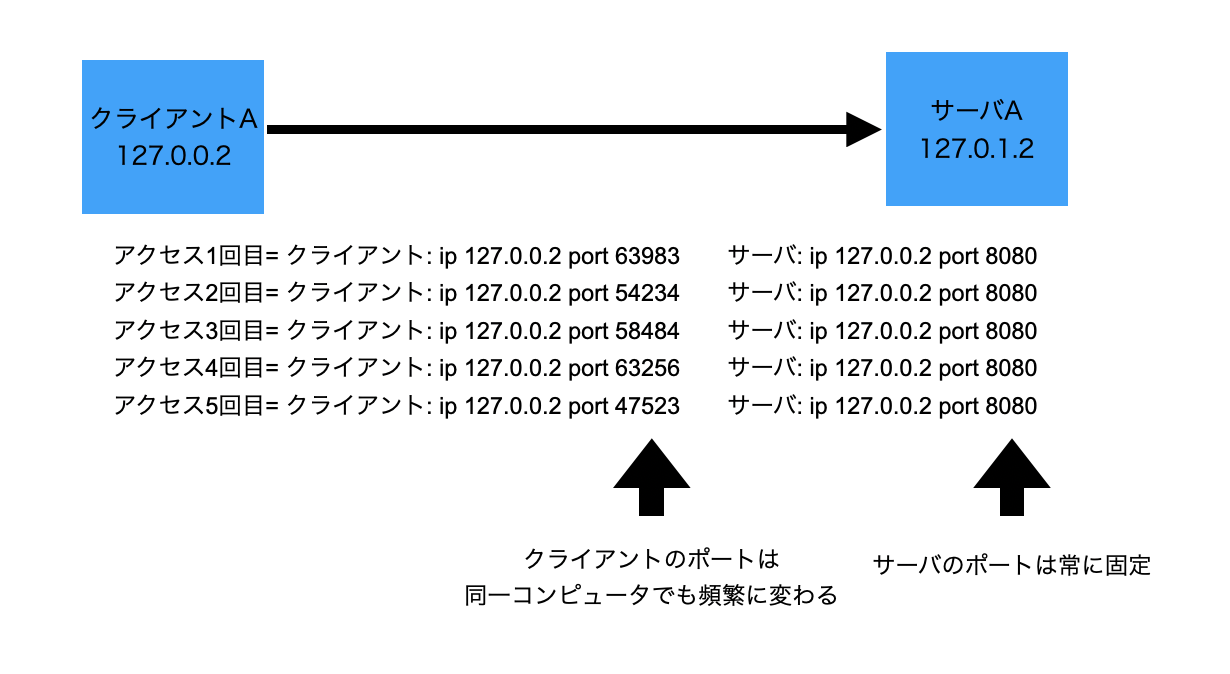
各システムごとの通信には、接続元IP、ポート番号、接続先IP、ポート番号が必要となる。
各システムの間の通信はIPとポート番号が重要になります。接続元(クライアント)・接続先(サーバー)ともにIPとポート番号を用意して通信します。
クリックすると拡大できます
IPがインターネット上の住所であるのに対して、ポート番号が受け口・発進口の役割をしています。上の図にあるように接続先ポートは接続元クライアントが通信を行うために事前把握が必要であるため、固定値として定めているという特徴があるのに対して、接続元ポートは通信を受け取ったサーバーだけが知っていれば良いため、ランダムな値が作成されることがほとんどです。
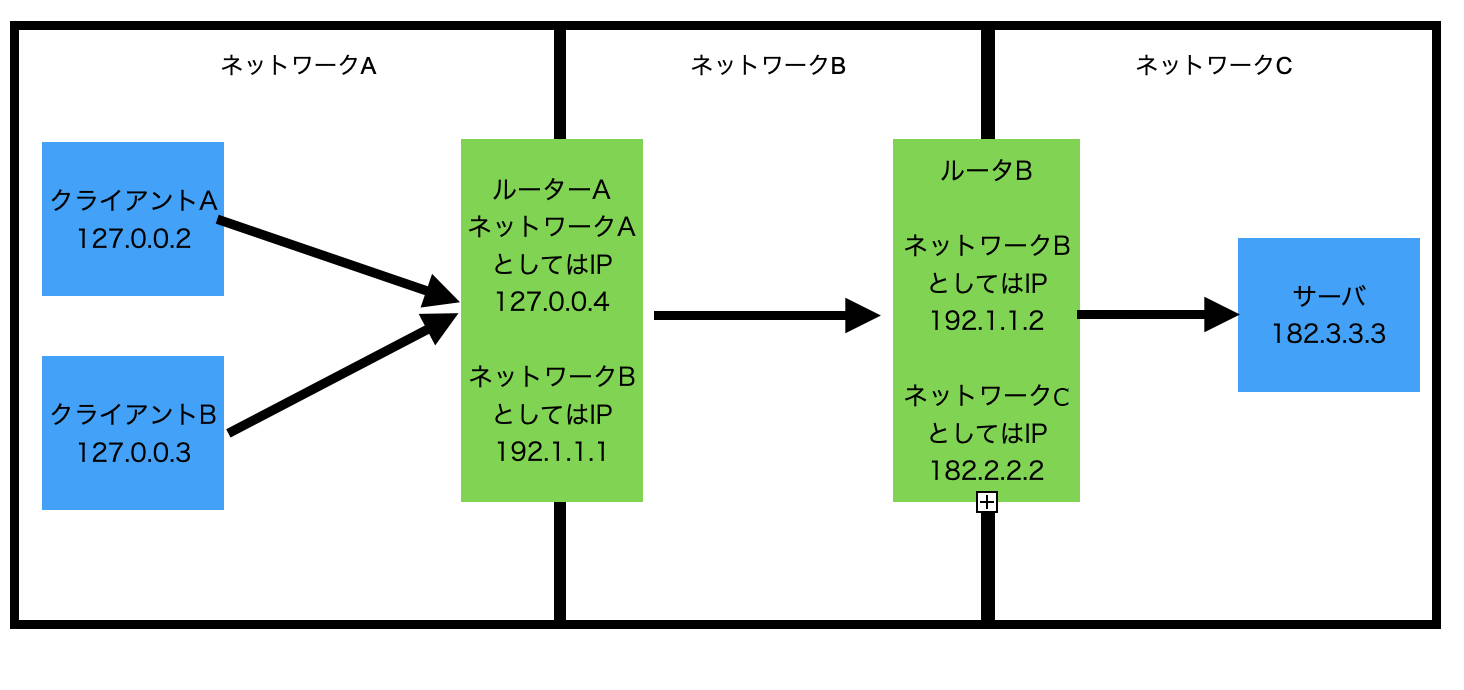
ユーザーがWEBサービスにアクセスするまでにはさまざまなシステムを通る
インターネットは巨大なネットワークです。私たちがPCやスマートフォンでサーバにアクセスする時、直接アクセスしたいアプリケーションサーバーにアクセスしているわけではありません。ルーターという中継システムがいくつもあり、クライアント端末のIPが直接サーバーに伝わるわけではありません。
クリックすると拡大できます
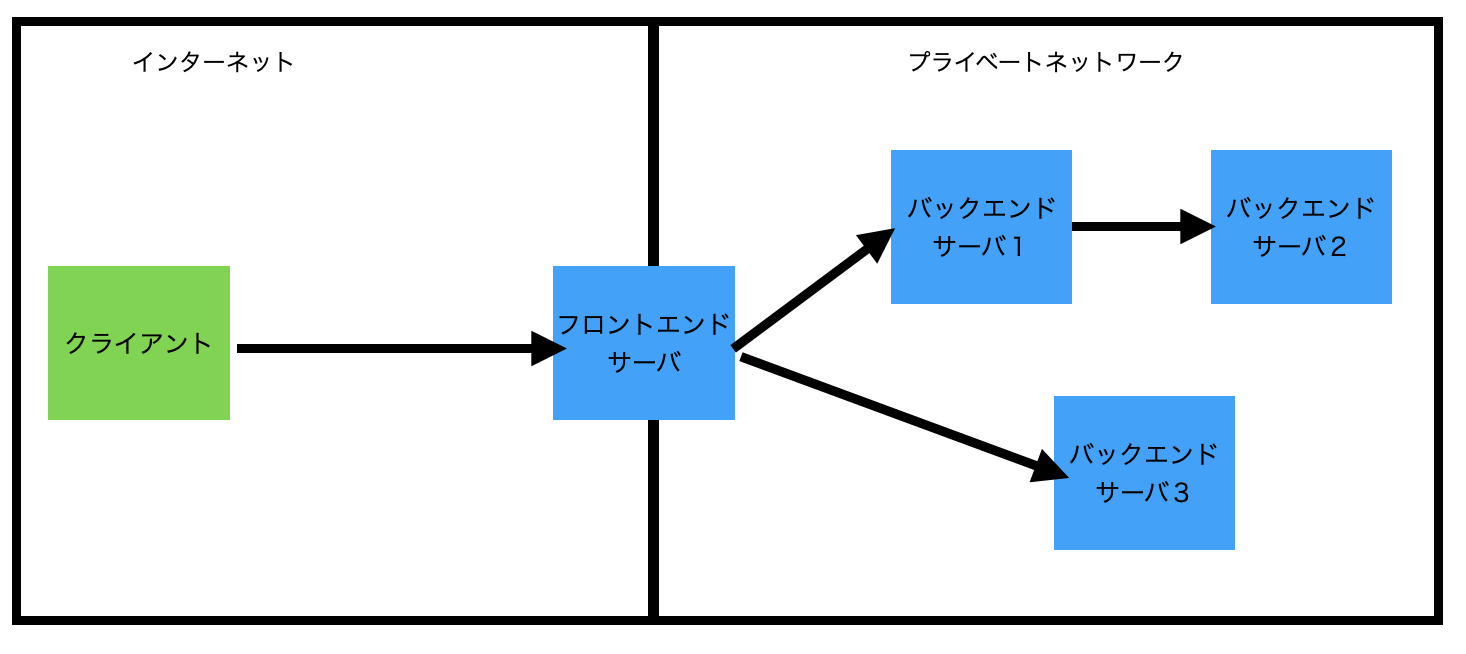
これはクライアントサイドだけの話ではありません。サーバサイドも同様の仕組みとなっています。実際WEB事業者がクライアントに通信を受け付けている口であるフロントエンドサーバーでは、当該WEBページの表示データの作成などはやっていないことがほとんどです。実際は後ろにあるバックエンドサーバーにさらに通信をつないでいます。
クリックすると拡大できます
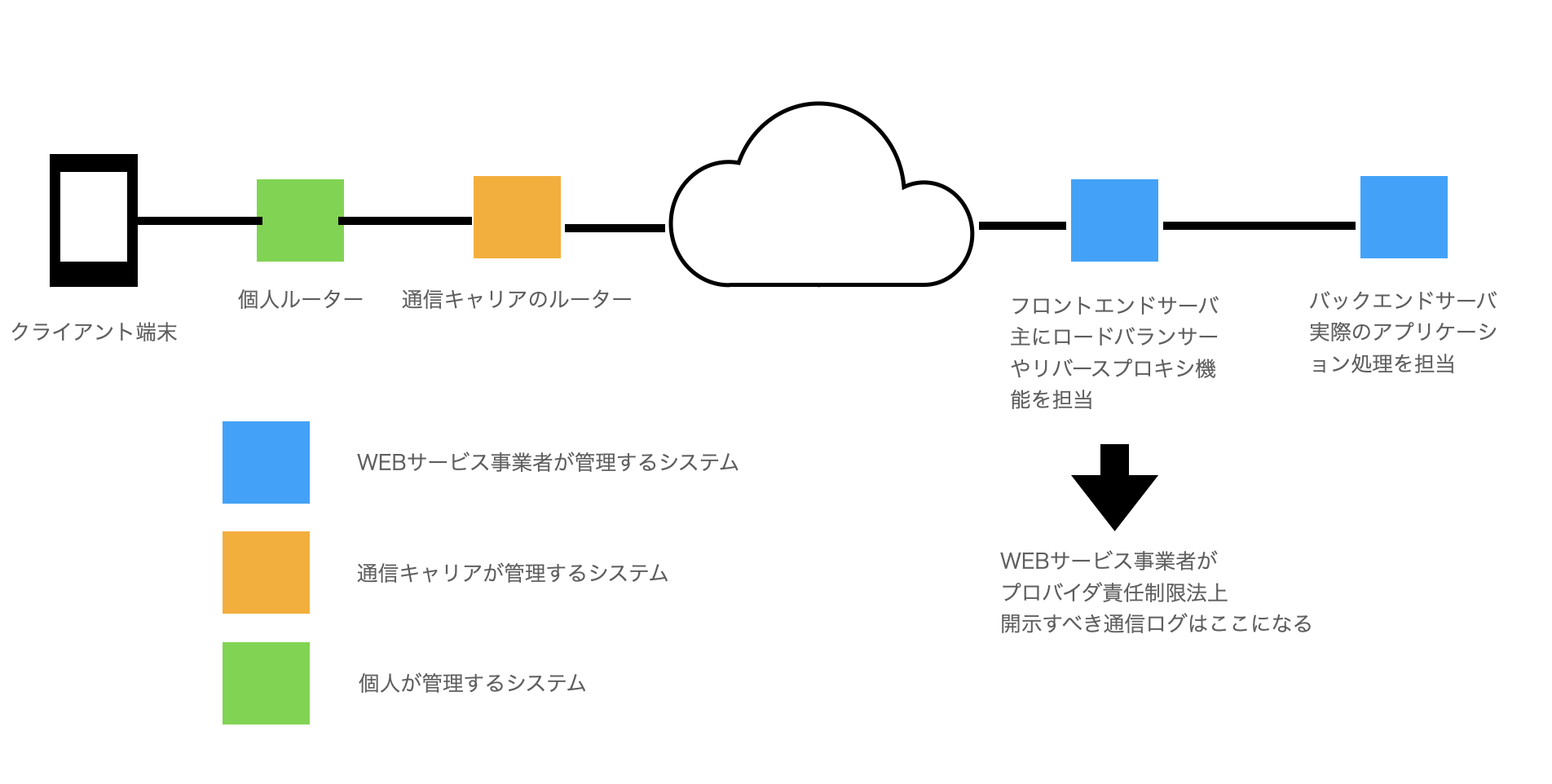
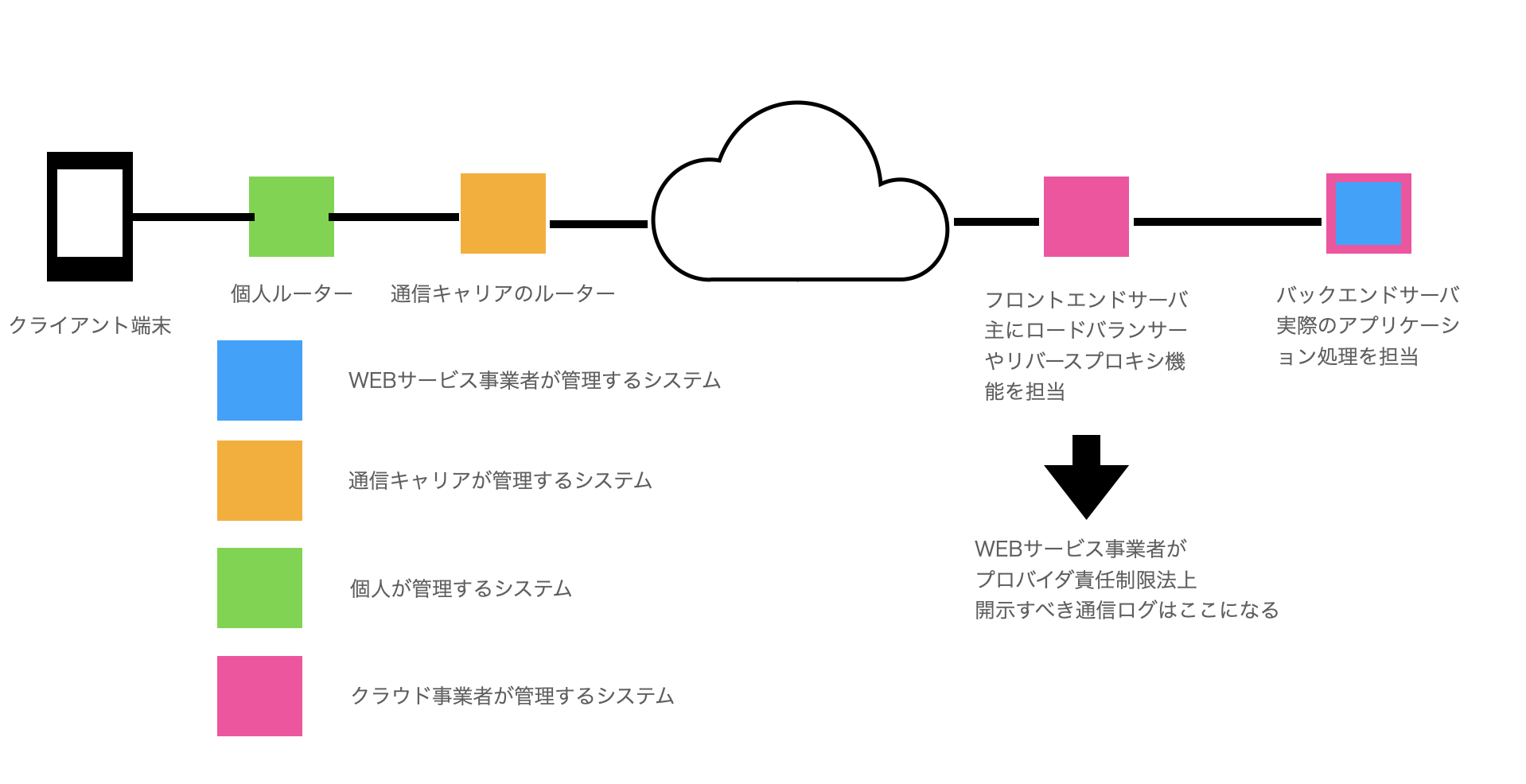
ここまでの全体図を表すと以下のようになります。WEB事業者のプロバイダ責任制限法観点だと、開示請求がきた際にフロントエンドサーバーのログを出すことが必要ということになります。
クリックすると拡大できます
システム間の通信を実現する約束事としてプロトコルがある・プロトコルはレイヤーで分かれている
通信にあたってはさまざまな「プロトコル」という開発者間での仕様設定の約束事があります。この約束事によって、メーカーやソフトウェアが全く異なるシステムであっても正しく通信ができる仕組みになっています。
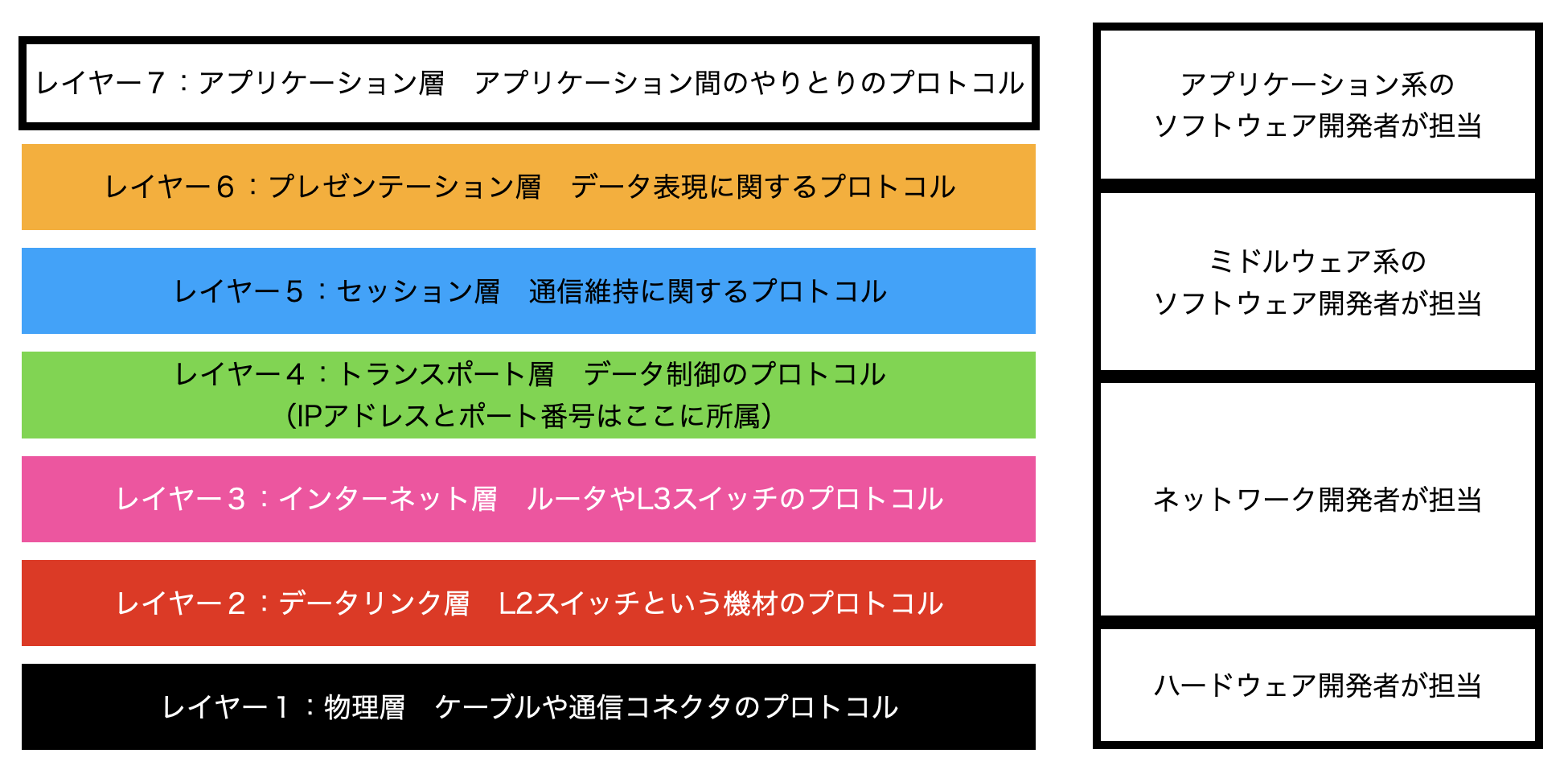
プロトコルはさまざまな種類があり主にレイヤーで分類されています。以下はOSI参照モデルというレイヤーの関係を表した図です。
クリックすると拡大できます
実はここまで述べてきたIPアドレスやポート番号もプロトコルの一種です。レイヤー4の通信層のプロトコルに所属しています。
プロトコルがレイヤーに分かれることのメリットとして、各開発者が担当するレイヤーのプロトコルだけを覚えて開発すれば良いというメリットがあります。上の図の右が一般的な各レイヤーの担当開発者です。
今回、この記事を執筆する私も、すべてのレイヤーのプロトコルに詳しいわけではありません。ある程度詳しく知っているものはレイヤー4以上が限界です。もちろんレイヤー4以上もスペシャリストを自負できるほどでもありません。そのほかのレイヤーについては一般教養程度にとどまっております。
一方で、レイヤーが別れることにはデメリットもあります。特定のレイヤーしか担当しない開発者は他のレイヤーのプロトコルに干渉しづらいことです。もしも開発しづらい・運用しづらい欠点があったとしても修正を働きかけることが難しいということです。
WEB事業者は一般的にはソフトウェア開発者であるため、上位レイヤーしか担当しません。大手IT企業であれば、レイヤー3レベルまでコミットできるところもありますが、クラウド化などの流れを考えるとレイヤー7、レイヤー6レベルしかコントロールできない事業者がほとんどになり始めています。
後に述べますが、このレイヤーに分かれることのデメリットが、WEB事業者がプロバイダ責任制限法対応するにあたって課題となる遠因であると私は考えています。
通信データはレイヤープロトコルごとのHeaderとBodyに分けられる
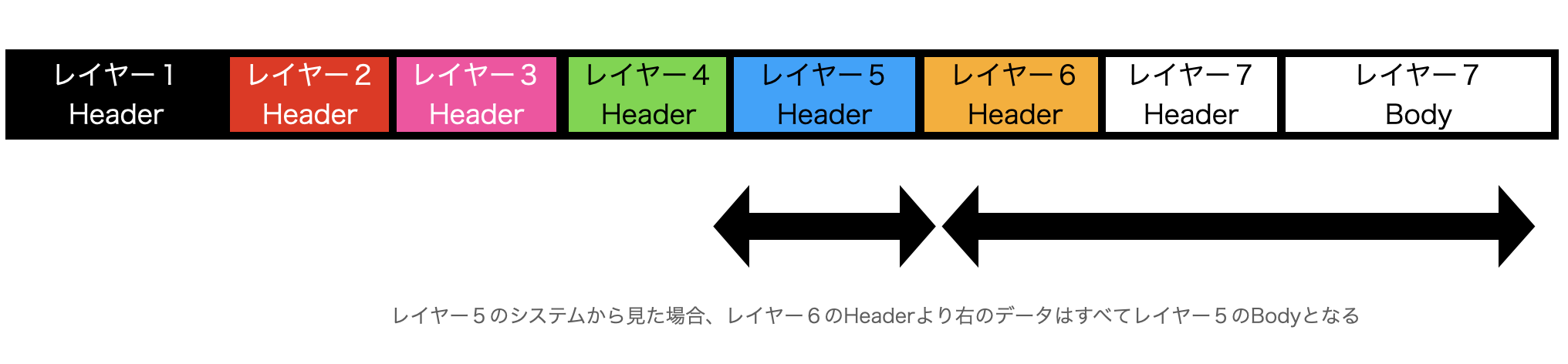
通信データを以下の図であらわすとこのような棒型のものになります。着目していただきたい点はレイヤープロトコルごとのHeaderとBodyに分けられる点です。
クリックすると拡大できます
上の図ではレイヤー7しかBodyが無いようにみえますが、そういうことではありません。各層ごとにどのデータをHeaderとBodyに分けてみるのかが変わる仕組みになっているからです。その結果、純粋にBodyとしか扱われないデータが存在するのはレイヤー7に限定されるからです。
レイヤー4の場合、レイヤー4のHeaderより右の情報は、上位レイヤーにとってはHeader情報であってもレイヤー4の通信プロトコル上のBodyとなります。一般に低位レイヤーにとってBodyとなるところは、上位レイヤーのシステムの仕様やプロトコルの邪魔にならないようにするため、中身を解析したり加工することはありません。
逆に、上位レイヤーにとってのHeaderより左にある情報は、上位レイヤーにとっては加工したり触ったりすることはもちろんできませんし、プロトコルやシステム、ミドルウェアの仕様によっては中身を閲覧することもできないことがあります。
これは今回後に述べるようなプロバイダ責任制限法対応の課題を発生させている一方で、不正防止が期待できる側面もあります。例えばIPアドレスはレイヤー4であるため、主に通信事業者が司っています。通信事業者は日本においては電気通信事業法の届け出をしている事業者であるため、レイヤー4以下の機器に不正が働く余地が少ないことが期待されます。
何らかの届出漏れや海外経由の通信といった、野良ネットワークを介したインターネット通信発生しない限り、IPアドレスを偽装したり改竄することが難しくなることを意味しています。
IPアドレス・ポート番号はヘッダーから取得する
前述したように、WEB事業者はミニマムなところだと、レイヤー6、7のプロトコルしか触れません。そのため、レイヤー4~7の世界に存在するプロトコルを利用してIPアドレスやポート番号を取得することになります。
この層だけでもさまざまなプロトコルが存在しますが、一般的にWEB事業者が利用するプロトコルはブラウザの通信でよくつかうHTTP/HTTPSプロトコルです。
IPアドレスやポート番号を取得する場合、HTTP/HTTPSプロトコルにおけるHeader情報から当該情報が保存されているものを取り出して、ログやデータベースに保存することで管理しています。
接続元の情報がわかるHeaderは以下の通りです。なお、このHeader情報は厳密には標準団体がプロトコルとして定めておらず、各プログラム言語、ミドルウェアによって異なります。それでも、ほとんどのものが同一Header名で利用できるようになっています。
- RemoteAddr:接続元のIPアドレス
- X-Forwarded-For:クライアント含むこれまで経由したシステムのすべてのIPアドレス
- X-REAL-IP:クライアントのIP
※このHeader情報は私が把握している限り、Nginxというミドルウェアと一部のオラクル製品しか対応してないようです。 - RemotePort:接続元のポート番号
ちなみに、実務的にはIPアドレスに関してはX-Forwarded-Forで取得することがほとんどです。X-Forwarded-Forであればすべての経由IPが取得されているからです。
今日通信量が多くてIPアドレスだけでは特定できないという課題から、プロバイダ責任制限法の総務省令ではリストアップされていない接続先IPの開示を求める請求者も増えています。
ここでは、法的請求で接続先IPも開示可能かどうかの議論は避けますが、もしも事業者として任意に開示しても良いという見解であるならば、X-Forwarded-Forを保存して管理していれば、こうしたニーズも対応することができるようになります。
なお、X-Forwarded-PortというHeaderも存在しますが、こちらは接続先のポート番号しか保存しておらず、プロバイダ責任制限法対応で必要な接続元ポートを取得することができません。ポート番号を保存・管理する場合はRemortPort一択になります。
前置きが長くなりましたが、WEB事業者におけるプロバイダ責任制限法対応と、その課題を考える上で必要な情報は一旦以上です。ここからは現実的な対応の難しさを述べていきたいと思います。
最大のネックは接続元ポート番号
いきなり結論を言ってしまうと、最大の課題は接続元ポート番号の取得管理が難しい点です。以下のように、さまざまな課題があるためです。
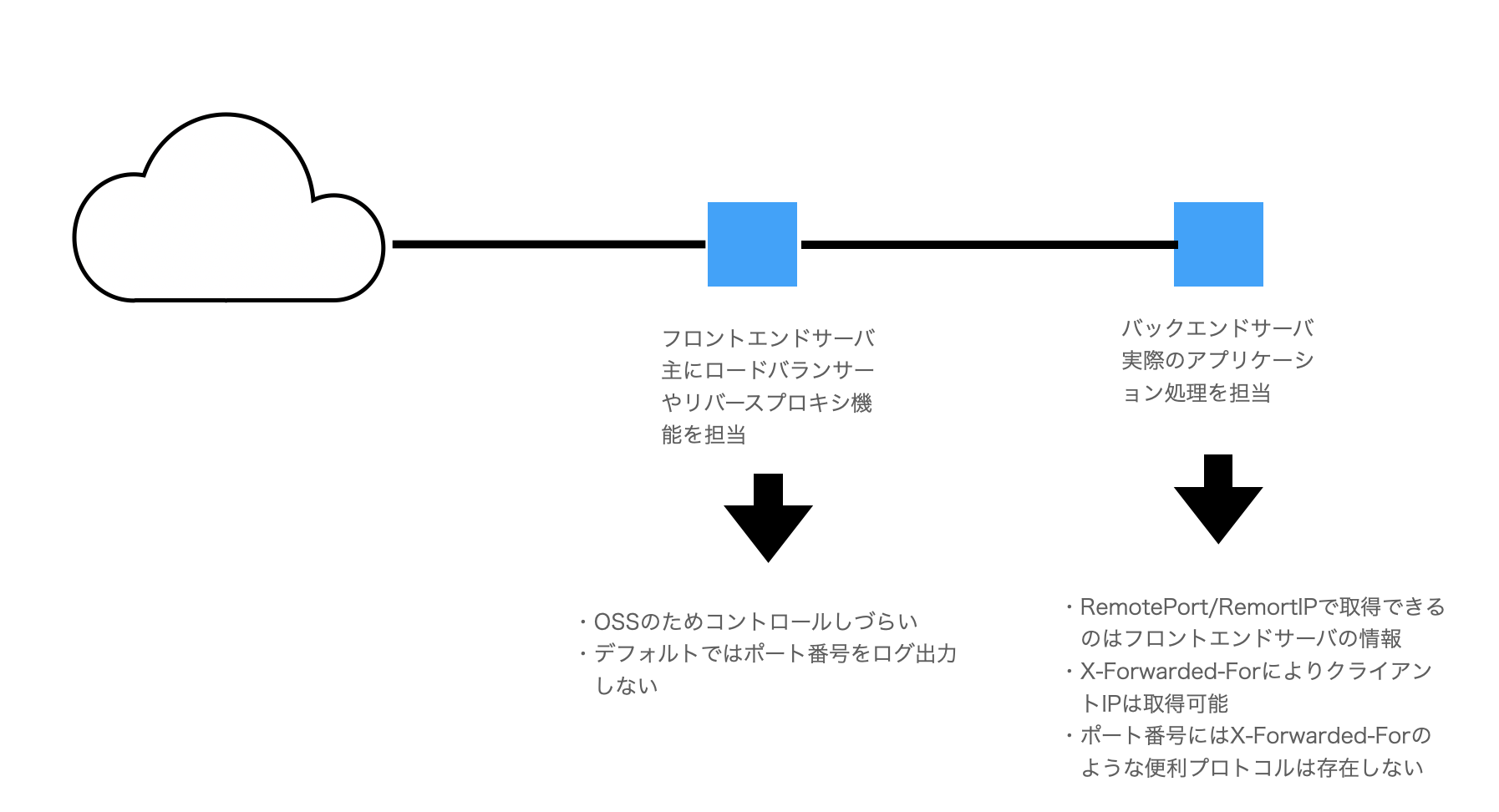
ほとんどのWEBサービスはアプリケーションサーバがフロントエンドサーバというわけではない・フロントエンドサーバはOSSなどのミドルウェアであることがほとんど
知識のおさらいで述べたように、WEB事業者のサーバサイドもフロントエンドサーバとバックエンドサーバを分け、単一サーバでシステムを運営しているわけではありません。これは負荷分散・セキュリティ対策を行うためです。
クリックすると拡大できます
この実情がプロバイダ責任制限法において、大きな課題を生み出しております。
WEB事業者が1から開発して運営するサーバーはアプリケーションサーバにあたるバックエンドサーバーがメインとなり、プロバイダ責任制限法上開示対象となる発信者情報を管理しているIPとポート番号を管理しているサーバは他社の製品やOSSに頼るということが現実になります。
クリックすると拡大できます
この結果によってもたらすのが、フロントエンドサーバーのコントロールに制限が課されるということです。残念なことに、今日ほとんどの製品やOSSにおいて、IPアドレスをログに落とす仕様はデフォルトとしてあるものの、ポート番号までログに落としてくれるものがありません。もしもポート番号取得をするのであれば、仕様書を頼りにチューニングをしたり、どうしても仕様上チューニングができないのであれば当該製品やOSSの利用を断念する以外方法がありません。
参考:NGINXを使ってIPアドレスとポート番号を取得する方法
ややマニアックな話になりますが、参考までにNGINXを使ってIPアドレスとポート番号を取得する方法をご紹介します。
以前こちらのIPアドレスとポート番号の確認ツールをご紹介しました。
以下の記事でご紹介したように、私が運営している当該ブログも同様のフロントエンドーバックエンドのシステム構成を採用しています。そして、フロントエンドはNGINXというリバースプロキシ機能を持つミドルウェアを利用しています。
参考までに、上記ツールを作るにあたって行ったチューニングをご紹介します。
クリックすると拡大できます
このミドルウェアも当然、デフォルトではポート番号を取得しません、そのため、以下のような設定ファイルを作成してチューニングしています。詳細は割愛しますが、X-Real-PortというオリジナルのHeader情報を作成して、クライアントのPort番号をバックエンドサーバでも閲覧できるように修正しています。
location /app {
proxy_pass http://127.0.0.2:8080/app; ←バックエンドのアクセス先
proxy_set_header X-Real-PORT $remote_port; ←X-Real-PortというオリジナルのHeader作成
}
図で示すと以下のようになります。
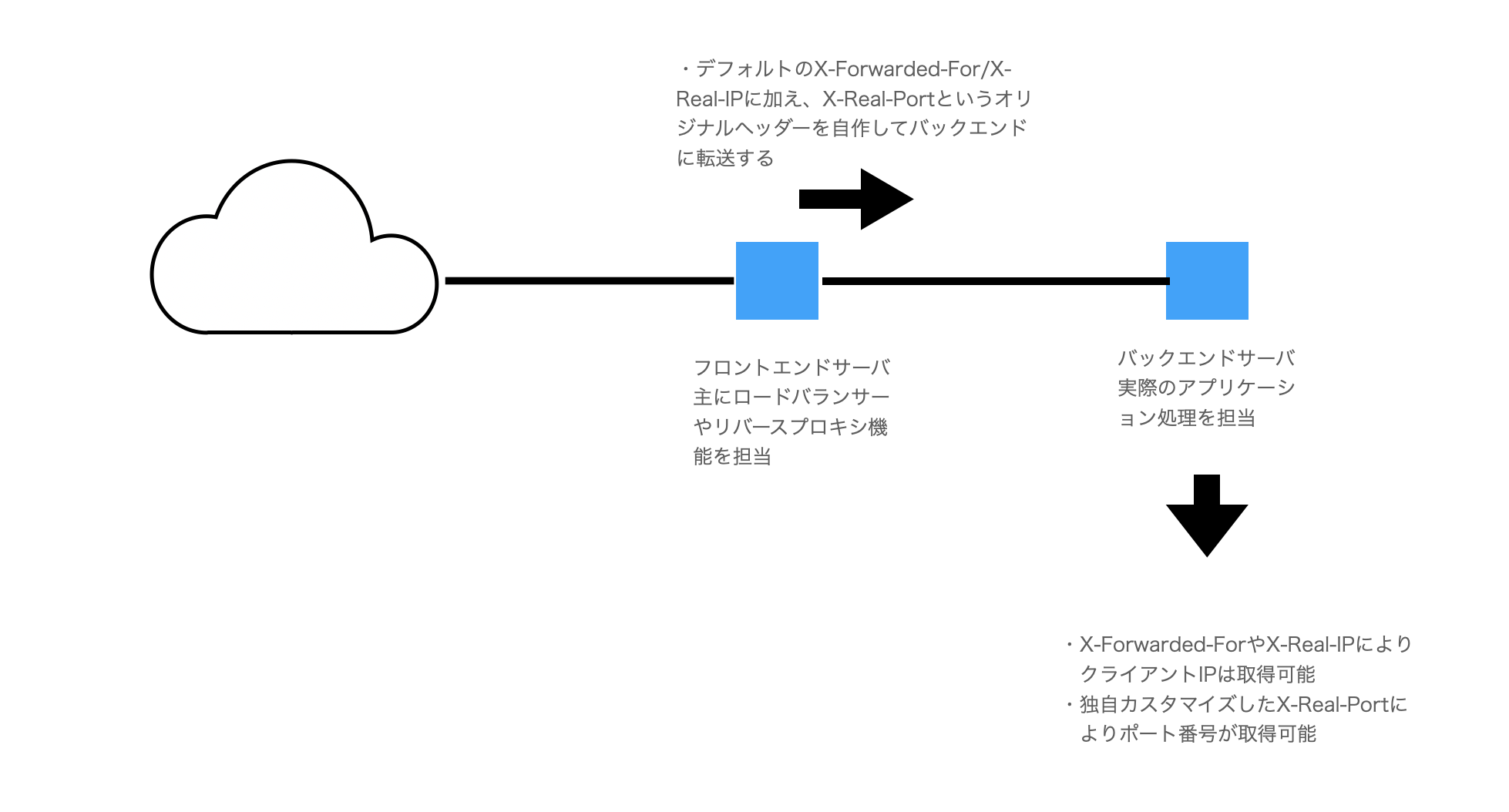
クリックすると拡大できます
このようなチューニングが可能であればポート番号取得対策は可能ですが、統一ルールはおろか、慣習さえ存在しないため、すべてのミドルウェアや製品でうまくいくとは保証できないのが実情です。
AWSなど主要クラウドのIaaS/PaaS/FaaSでWEBサービスを運営していると取得が絶望的になる
AWS・GCP・Azure筆頭に、WEB事業者のWEBサービス運営もクラウドのIaaS/PaaS/FaaS上で運用するということが加速しています。前掲の全体アーキテクト図も以下のような図になり始めており、WEB事業者がコントロールできる部分が減り始めています。
クリックすると拡大できます
これが意味することは、フロントエンドサーバが完全にコントロールができなくなり、WEB事業者がポート番号を取得することが不可能になるということを意味します。
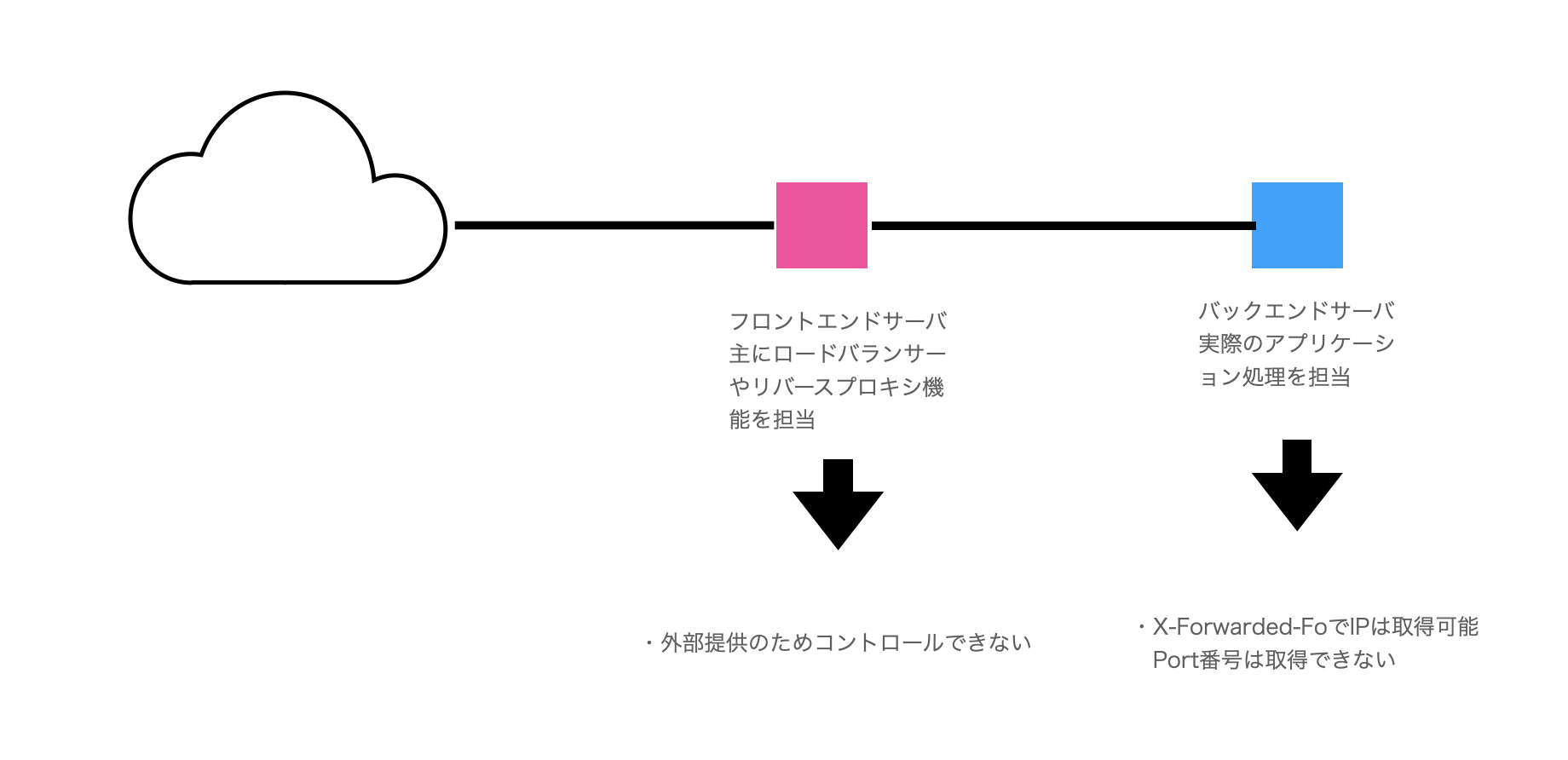
クリックすると拡大できます
この問題はサーバレスというPaaS/FaaSと呼ばれるプラットフォームを利用したWEBサイトが増えることでさらに加速しています。
負荷分散の観点上、事業者レベルでフロントエンドサーバとバックエンドサーバを分けることはまずないのですが、仮にフロントエンドサーバをアプリケーションサーバとして構築したとしても、当該プラットフォームが取得をそもそもできないけーすがあります。
たとえばFaaSの代表である、AWSLamdaでみてみましょう。
そもそもAWSLamdaはAPIGatewayというフロントエンドサーバを利用して使うことが前提のプラットフォームでありますが、こちらの仕様書にあるように、X-Forwarded-ForのHeader情報は取得できるもののRemotePortは取得することはできません。
あまり実務観点ではこのような説明はしませんが、プロトコルの概念を利用して説明すると以下のようになります。
HTTP/HTTPSというプロトコルは一般的にレイヤー5-7をカバーするプロトコルでありますが、このAWS Lamdaを使った場合、このHTTP/HTTPSを直接触ることができません。AWS LamdaがHTTP/HTTPSの通信データをコントロールしているからです。
AWSLamdaは、HTTP/Httpsの通信データの中から、データを選別し、利用者に取得しても良いと判断した情報だけを、レイヤー7のHeader情報として提供しているのです。この結果RemotePortは外されて、X-Forwarded-Forだけが残されてしまいました。
接続元ポートは通信ごとに毎回ランダムで変わるため正確な値の検証ができない
ここまで、仕様上の実装困難性を述べてきましたが、仮に実装できたとしても課題がまだあります。知識のおさらいで述べたように接続元ポートが毎回ランダムで付与される点です。
この仕様の結果、見た目上はクライアント端末の接続元ポートを取得したのか、それともプログラムやチューニングにバグがあり、間違ってフロントエンドサーバのポート番号を取得したのか判断することができません。
これが意味することは、発信者情報の開示で間違ったポート番号を開示してしまうリスクが大きいということです。発信者情報の開示請求されるということは、ほとんどの場合民事上の損害賠償責任や、刑事上の犯罪に問われていることを意味します。
最悪のシナリオは以下のようなものです。
- IPアドレスとタイムスタンプは正確であったものの、うっかり間違ったポートを提供してしまった。
- 開示請求者が続けて再照会した通信キャリアなどのアクセスプロバイダでは、たまたま同一タイムスタンプの接続元IPが複数あり、最後の決め手がポート番号となった。
- 結果として、間違ったポート番号で発信した発信者に対して、発信の罪や責任を問われることになってしまった。
これは冤罪を招くことを意味します。WEB事業者としてはゾッとする話です。しかしながら、今日ではフロントエンドサーバをOSSやクラウドの他社サービスに依存していることを意味しており、依存先にバグがあるのかを確認することがますます困難になっています。
今後の動向としてWEBサイト運営者が恐れること
幸いなことに、プロバイダ責任制限法は、開示した際の発信者に対する賠償責任の免責が規定されているのみで、特段義務は課されていません。そのため、ポート番号以前にIPアドレスやタイムスタンプの保持も義務ではなく任意になります。
もっとも今日の情勢を見ると、被害者サイドは省令で定められた開示項目の義務化を求めており、油断が許されません。
この記事の最後に、趣味も含めたWEBサイト運営者全体が恐れる展開について述べていこうと思います。
ポート番号を含めた正確な発信者情報保存の義務化
まず考えられる展開として、この記事で述べたようにポート番号を含めた正確な発信者情報保存の義務化がされることです。
前述のようにポート番号を取得することは、容易になるどころか、ますます難しくなっている実態です。この状況であると、各種クラウド事業者やOSSがポート番号取得を容易にする仕様変更をしない限り、オールドスタイルの単一サーバで運営するか、フロントエンドサーバもコントロールできる事業者しかUGC(UserGenerateContents)型のWEBサービスを運営することができなくなります。
これは大手IT企業なら問題ないかもしれませんが、ベンチャーや私のようなフリーランス・個人事業主にとってはコスト増を意味しており、とても痛手となる義務化です。
単に保持の義務化ではすまず、「正確な情報の保持」まで義務化された場合、ますますハードルが上がります。技術的に難しいだけでなく、検証も難しい今の実態を考えると、この義務化は事業者に高度な技術力を要求することになります。
ひょっとしたら、新しいビジネスチャンスとして、プロバイダ責任制限法対策のための接続元情報管理代行プロキシサービスのような事業が生まれるかもしれません。現実的な例として、WEB決済関連はリスクが高いゆえに、決済代行事業という新たなビジネスが生まれています。いずれにしても、何らかの外部支援が始まらない限り、UGCサイト運営がますます困難になる可能性があります。
UGCを運営する際の利用者の本人確認の義務化
逆にIPアドレスやポート番号の取得を免除する要件として、会員限定サイトにして、氏名・メール番号・電話番号を取得して対応しようとしたWEB事業者も注意が必要です。これらの情報については本人偽装されるリスクが高いためです。
発信者の特定ということを重要視されてしまうと、決済やネット銀行開設といった高いセキュリティが必要とされないWEBサービスであっても本人確認義務などが課される可能性があります。本人確認はSMS認証・eKYCなど簡易化が進んではいるものの導入コスト・運営コストが引き続き高いというのも実態である点で注意が必要です。
前述の義務についてWEBサイト運営者すべてが対象となること
最後に最も恐れるのは、いわゆる営利活動をおこなわず、趣味で運営するWEBサイトも規制対象になることです。
電気通信事業法などと違って、発信者情報特定の問題は、「闇サイト」といった非営利サイトも含まれるため規制対象になる可能性はゼロではありません。こうなってしまうと、趣味でちょっとしたソーシャルゲームサイトを運営することさえ難しくなります。
終わりに
私のブログの法律系、IT技術系カテゴリの記事としては珍しく、非常にマニアックかつ難解な記事となってしまいました。総務省のヒアリングでは比較的大きなIT企業ばかりが登壇して見解の発表しているようですが、私の視点としては、本法律の今後の動向は、どちらかというと個人事業主・フリーランスのWEBサイト運営者、趣味でのWEBサイト運営者に大きな危機があるのではと思っています。私個人の雑記として述べたくなったのはこの背景があります。
最後まで読んでいただきありがとうございました。最後に述べた「プロバイダ責任制限法の今後の動向として、WEBサイト運営者が恐れること」は流石に杞憂な考えであることは事実ですが、少しでも何か気づきや発見があれば幸いです。
Photo by Markus Spiske on Unsplash



