
この記事について
インターネット利用でもっとも多いことはやはりブラウザでWEBサイトをみることではないでしょうか。この記事ではWEBサイトを閲覧するにあたってのネットワーク上の仕組み、WEB通信における仕組みについて解説していこうと思います。
前回、「教養としてのネットワーク入門 - インターネットの仕組み編」の続きになります。下記記事を前提にして書いておりますので、知識に不安がある方は事前に以下の記事を目に通しておいてください。
フロントエンドサーバとバックエンドサーバ
前回「教養としてのネットワーク入門 - インターネットの仕組み編」でプライベートネットワークという概念を出しました。これはクライアント側だけが活用しているものではありません。大規模なシステムほど、プライベートネットワークを活用し、インターネットという外部ネットワークに所属するサーバの数を限定しています。
インターネットのネットワークに所属し、直接外部ネットワークからのアクセスを受け入れるサーバのことをフロントエンドサーバといいます。逆にプライベートネットワークにのみ存在し、フロントエンドサーバをクライアントとすることで外部からの通信の処理を行うサーバのことをバックエンドサーバと言います。
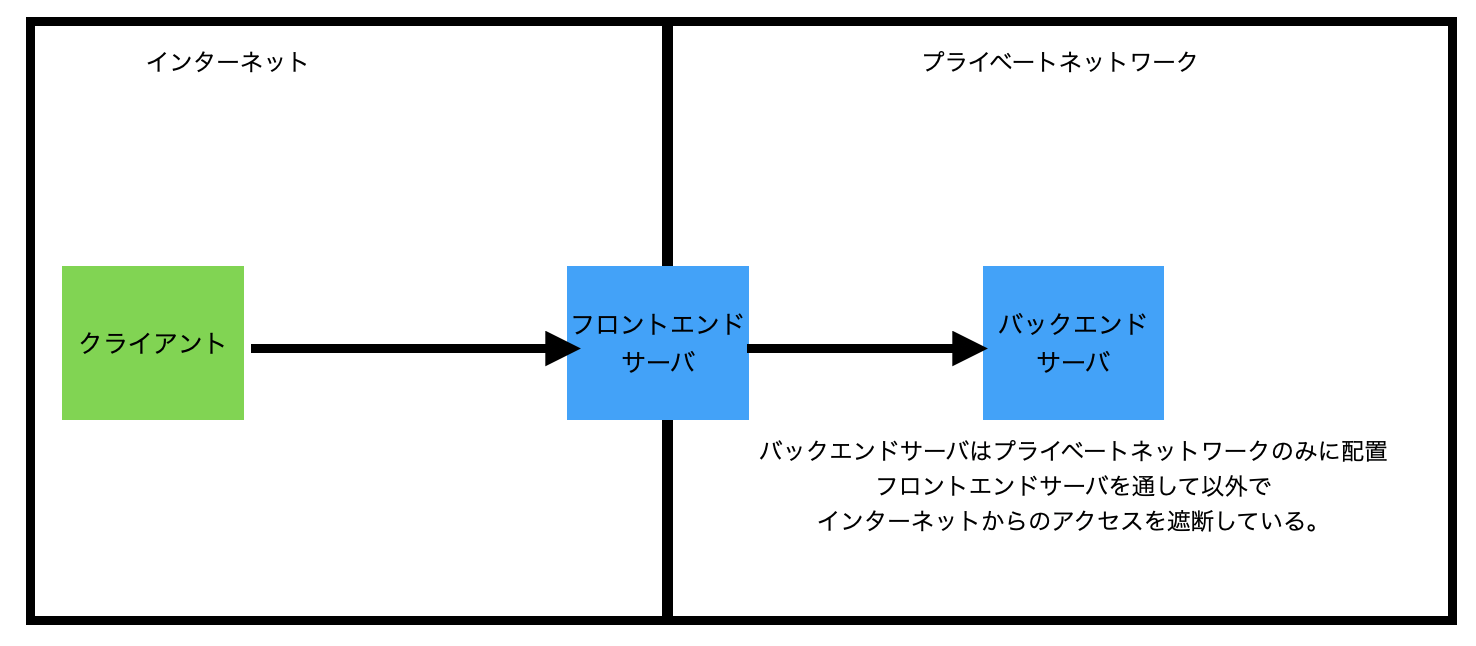
クリックすると拡大できます
バックエンドサーバのシステム構成は、システムによって様々です。複雑なシステムだと、以下の図のようにフロントエンドサーバが複数のバックエンドサーバにクライアントとしてアクセスをしていたり、バックエンドサーバもクライアントとして、さらにプライベートネットワークの奥底にあるバックエンドサーバにアクセスしていたりしています。
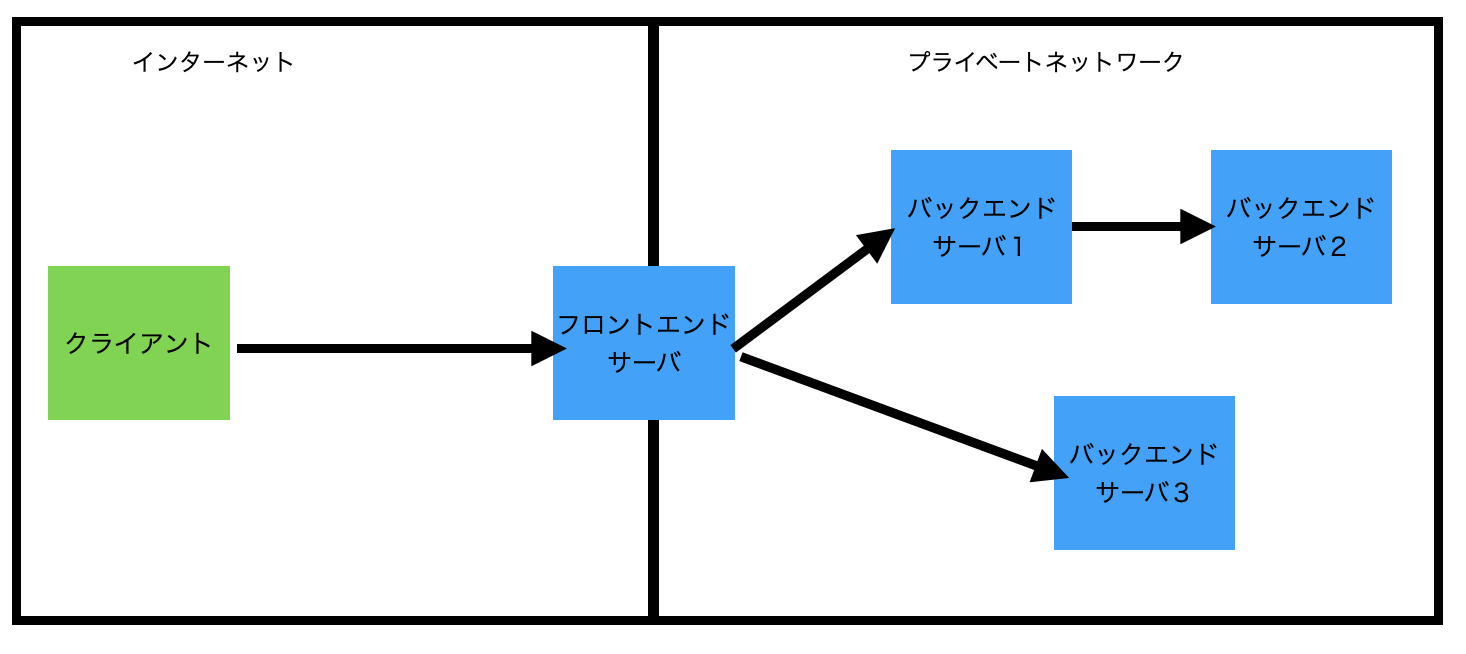
クリックすると拡大できます
このようにフロントエンドとバックエンドで役割分割をすることの目的は主にセキュリティ対策と負荷分散をするためです。
セキュリティ面としては、センシティブなデータをバックエンドサーバのみが管理して、フロントエンドサーバが直接管理しない構成にすることで、フロントエンドサーバが不正なアクセスを受けて乗っ取られたとしても、実際のデータ管理はバックエンドサーバである以上、即座に情報流出を防ぐ効果があります。
続いて負荷分散は、サーバごとに役割を分けることで、処理を分散させる効果があります。
例えば、以下のようにフロントエンドサーバを1種類だけ用意する一方、バックエンドサーバに2種類、APIサーバ、データベースサーバを用意した3層構造のシステムをみていきましょう。

クリックすると拡大できます
この場合、APIサーバだけがデータベースサーバのアクセスを可能にし、データ取得と加工を行う役割を持っています。この結果、フロントエンドサーバはユーザーアクセスを受け付けてデータを返すことに専念できます。加えて、APIサーバは、キャッシュを持つことで、データベースに頻繁にアクセスすることを防ぎます。このようにしてデータベースの負荷を削減しています。
フロントエンドサーバは有象無象の通信を受け付けるが故に、各通信の検証に専念させてあげた方がよく、同様にデータベースサーバは単にデータを持つだけでなく、バックアップ、メンテナンスといった処理を行っているため、それぞれのサーバにしかできない処理になるべく専念させてあげた方が合理的であるのです。
この他、クライアントサイドとサーバサイドシステムの応用として、プライベートネットワーク内に管理者PCを設置して、管理者PCだけがデータベースサーバに直接アクセスしてデータ集計やデータ管理をさせるといったシステム構成も作ることができます。管理者PCはインターネットに接続させないことで、安全にデータ管理をすることができます。

クリックすると拡大できます
URLの仕組み
続いて、URLの仕組みをみてみましょう。私たちが普段ブラウザに入力するURLは以下のような構成をとっています。

クリックすると拡大できます
それではそれぞれのパーツごとにみてみましょう。
スキーム
スキームとは、通信様式(プロトコル)を定義しているものです。一番有名なものはHypertext Transfer Protocolの略称である、HTTP(http://)とHTTPの通信を暗号化してセキュアにしたHTTPS(https://)ですが、この他PC内のファイルを確認するFILE(file://)などがあります。
ドメイン
ドメインは「教養としてのネットワーク入門 - インターネットの仕組み編」でも紹介しましたが、サーバのIPアドレスに紐づく名前です。DNSサーバを使った名前解決を通じてIPアドレスを取得します。
実はドメイン部分はIPアドレスに書き換え可能です。「https://127.0.0.1/hoge/fuga」というようにすることで名前解決を行わずに直接サーバにアクセスできます。
ポート番号
:8080などの形式でポート番号を指定できます。なお、httpはデフォルトが80、httpsはデフォルトが443と定められているため、デフォルトポートで稼働しているサーバ以外は省略可能です。
パス
パスは実際にサーバにアクセスして処理する内容を指定しています。
今回のような/article/file.htmlのような場合、「当該サーバの中にあるarticleフォルダの中のfile.htmlというファイルにアクセスさせてください」という意味になります。
もっとも必ずしもフォルダ・ファイル構成を記載するというわけではなく、getArticleListというようなサーバへのコマンド、命令を記載することもあります。
このあたりは当該サーバを実装した方の仕様定義によって変わります。
https://google.comだけでGoogleのトップページが表示されるように、パスの指定がなくてもデフォルトで表示するページを用意しているケースもあり、省略可能な値でもあります。
クエリ
?から始まる値のことをクエリと言います。サーバに特定の値を渡すときによく使われます。値を渡すことが不要なケースも多いため、この部分も省略記載可能です。
key=valueという形式で値を定義しています。複数ある場合は&で挟みます。今回例としてあげたURLの場合idというkeyで1234という値、optionというkeyで234という値の2種類を渡しています。
クエリが一番よく使われるケースは検索です。GoogleやYahoo!で検索をしたあと、URLをみてみてください。Googleでしたら、qというkey、Yahoo!の場合はpというkeyに検索ワードが入っています。
上述のように値を渡すことによく使います。クエリを使う場合は検索ワードのように共有を容易にしたいケースでよく使われます。
なおサーバへの値渡しにはもう一つ、URLではなくリクエストデータのBody部に記載して渡す方法があります。この方法ならURLで値を渡さないため、セキュアにデータ渡しをすることができ、IDとパスワードを使ったログインなどによく使われます。こちらは後述の「WEB通信の仕組み」で説明します。
Web通信の仕組み
続いてWeb通信でどんなデータが流れるかみてみましょう。
HeaderとBody
まずリクエスト時、クライアントからサーバにアクセスする際は以下のようなデータが送られます。
POST /app/network/post HTTP/1.1
Host: miyau5555.info
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36
Referer: http://miyau5554.info/
body=my name is miyau5555&title=hello
続いてレスポンス時、クライアントからのリクエストを受けてサーバがクライアントにデータを返送する際には以下のようなデータが送られます。
HTTP/1.0 200 OK
Date: Tue, 10, Feb 2020 23:59:59 GMT
Content-Type: text/html; charset=iso-2022-jp
Content-Length: 1234
<html>
<head>
<title>Hello</title>
</head>
<body>
<h1>Hello</h1>
<p>Welcome to Http!</p>
</body>
</html>
現時点では何が書いてあるのかは分からなくて問題ありません。1点だけ、どちらも一行空白を開けてデータがグルーピングされている点に注目してください。上部分をHeader、下部分をBodyといいます。このようにWEB通信においてはHeaderという情報、Bodyという情報の2種類の情報をやりとりしています。
Header
Header部分は通信にあたってのメタ情報が入っています。リクエスト時は、URL、Referer(直前に閲覧していたサイト)、Cookieなどが記載され、サーバに送られています。レスポンスの時は、実際の応答の成功有無などが記載されクライアントに送られています。
Body
Body部分は、リクエスト時にはサーバに送りたいデータ、レスポンス時には実際にブラウザに出力させるデータが入っています。レスポンス時には主にHTMLという、ブラウザが解析してプログラムコードが入っています。この生データはブラウザ上で右クリックして「ページのソースを表示」をすることでみることができます。
なお、リクエスト時にはBody部のデータが空のケースも多いです。後述するRequestMethodがPost通信時にはサーバに送りたいデータが記載されますが、単にURLで指定したページを閲覧したいだけの時はBodyには何も入っていません。
実際に中身をみてみる
それでは実際の通信の中身を、ブラウザ操作をしながらみてみましょう。今回はGoogleChromeのブラウザが提供しているデベロッパーツールを使います。
デベロッパーツールを立ち上げるには、ブラウザアプリ右上のメニューから「その他のツール」を選択肢し、さらに「デベロッパーツール」をクリックしてください。
クリックすると拡大できます
下記のようなツールが立ち上がります。これがデベロッパーツールです。エンジニア向けに実際の通信やりとりの内容、受け取ったデータの処理内容を確認できるツールです。
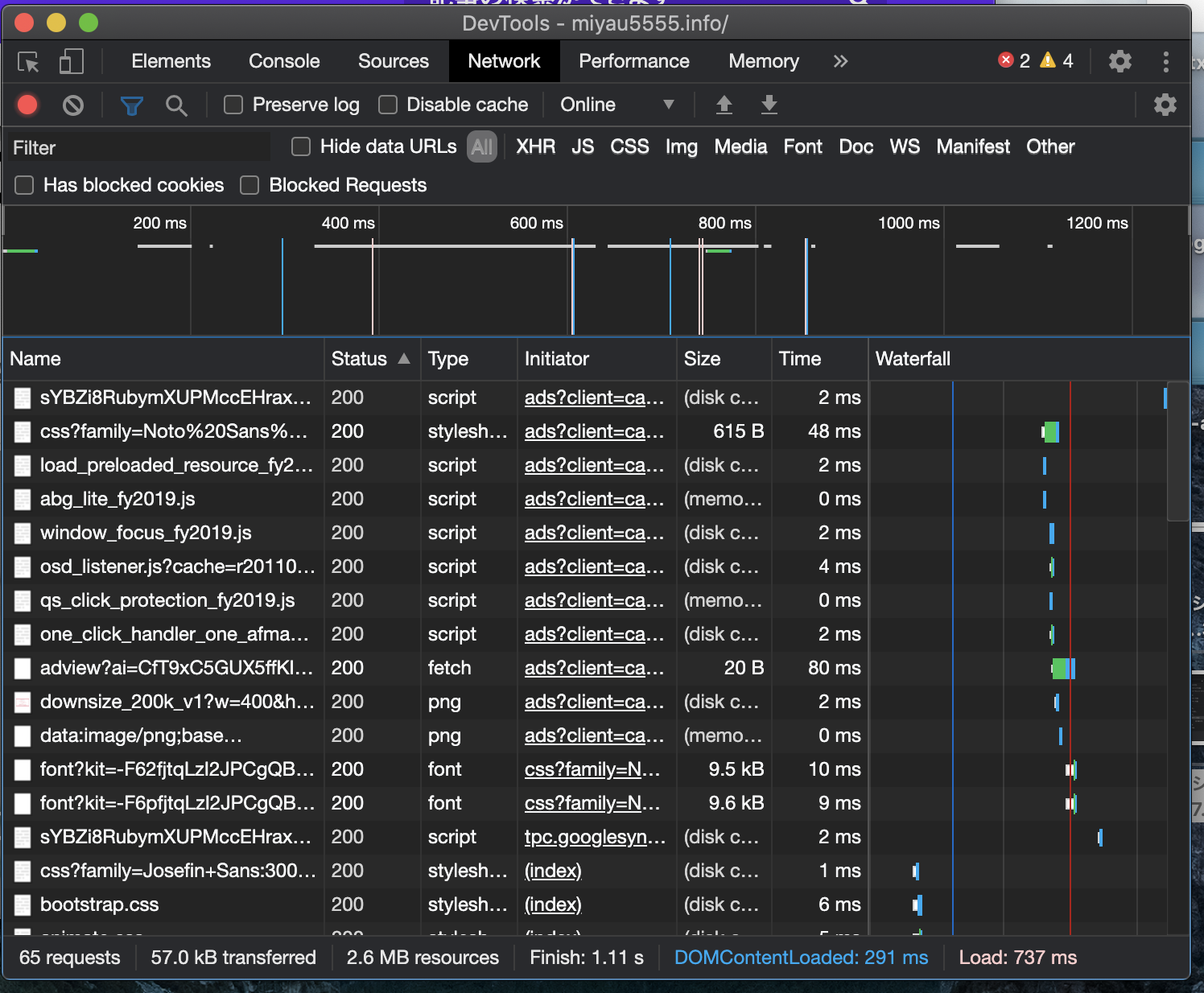
クリックすると拡大できます
デベロッパーツールを開いたら上部のNetworkのタブを開きましょう。Networkタブを開いたら、任意のウェブページを開いてみてください。上記の画像のように当該WEBページを表示する上で行った通信の記録が出てきます。
通信記録がでたら、一つ任意の行をクリックしてみてください。下の画像のように「Headers - Preview - Response - Initiator - Timing - Cookies」という画面がでます。この画面のHeadersタブをクリックしてください。クリックすると当該行で行った通信でやりとりされたHeader情報をみることができます。

クリックすると拡大できます
知っておくと便利なHeader
デベロッパーツールを使いながら、代表的なHeader情報をみていきましょう。
RequestHeader
まずRequestHeaderの代表的な値を紹介します。
Request URL
Request URLは文字通り、リクエストしたURLです。基本はブラウザのURL欄に入力される値です。※GoogleChromeのデベロッパーツールではGeneralの欄に記載されています。
UserAgent
UserAgentとは現在アクセスしているクライアントの端末とブラウザのアプリケーションの情報です。サーバはUserAgentの中身をみて、モバイルサイト用のデータを返すか、PCサイト用のデータを返すかなどの判別をしています。
Cookie
Cookieはブラウザとサーバ双方でやりとりするデータです。元々はサーバから受け取り、ブラウザ側で保存していたデータでありますが、サーバへの再アクセス時にHeaderにCookieを記載して再度サーバに送信する性質があります。
このCookieを一番よく使うケースはユーザーのログイン管理です。初めてサーバにログインしたときにサーバはユーザーを識別できる値が入ったCookieをブラウザに保存させます。クライアントとなるブラウザは、再度サーバへリクエストをするときに保存したCoookieを一緒に送信してくれるので、サーバは受け取ったCookieでログインずみかどうか確認ができます。もしもユーザー識別子が当該ログインユーザーであった場合は、ログイン済ユーザーとして、再度IDとパスワードの入力することなしでアクセスを許可します。
上述のようにCookieはログイン管理に使われるため、プライバシー上センシティブなデータが入ることが多く、ここの値の漏洩に配慮するようにサーバ側は対策する必要があります。
Request Medhod
Request Methodはリクエストをする際の通信の種類を定義しています。様々な種類がありますが、ここではGETとPOSTだけ紹介します。
GET
WEBページのリンクをクリックしたとき、URL入力欄にURLを入力したときに利用するMethodです。GETの名称の通り、データ取得を目的とするMedthodのため、URLとHeader情報以外の情報を送ることはありません。リクエスト時にはBody部になにもデータが入りません。
POST
GETとは異なり、ブラウザから何らかのデータを渡すときに使うMethodです。リクエスト時にBody部に送信したいデータをいれます。入力フォームを設けたのWEBページのデータ送信でよくつかいます。
私の方でPOST通信体験ページを用意しました。こちらはテキストフォームに入力した値を送信すると、受け取った入力テキストを表示させる簡単なWEBアプリです。

クリックすると拡大できます

クリックすると拡大できます
このWEBアプリをデベロッパーツールで通信内容の監視をしながらみてみましょう。ネットワークタブに表示される通信記録の一番先頭にpostというパスが表示されますのでこちらのHeadersを確認してください。
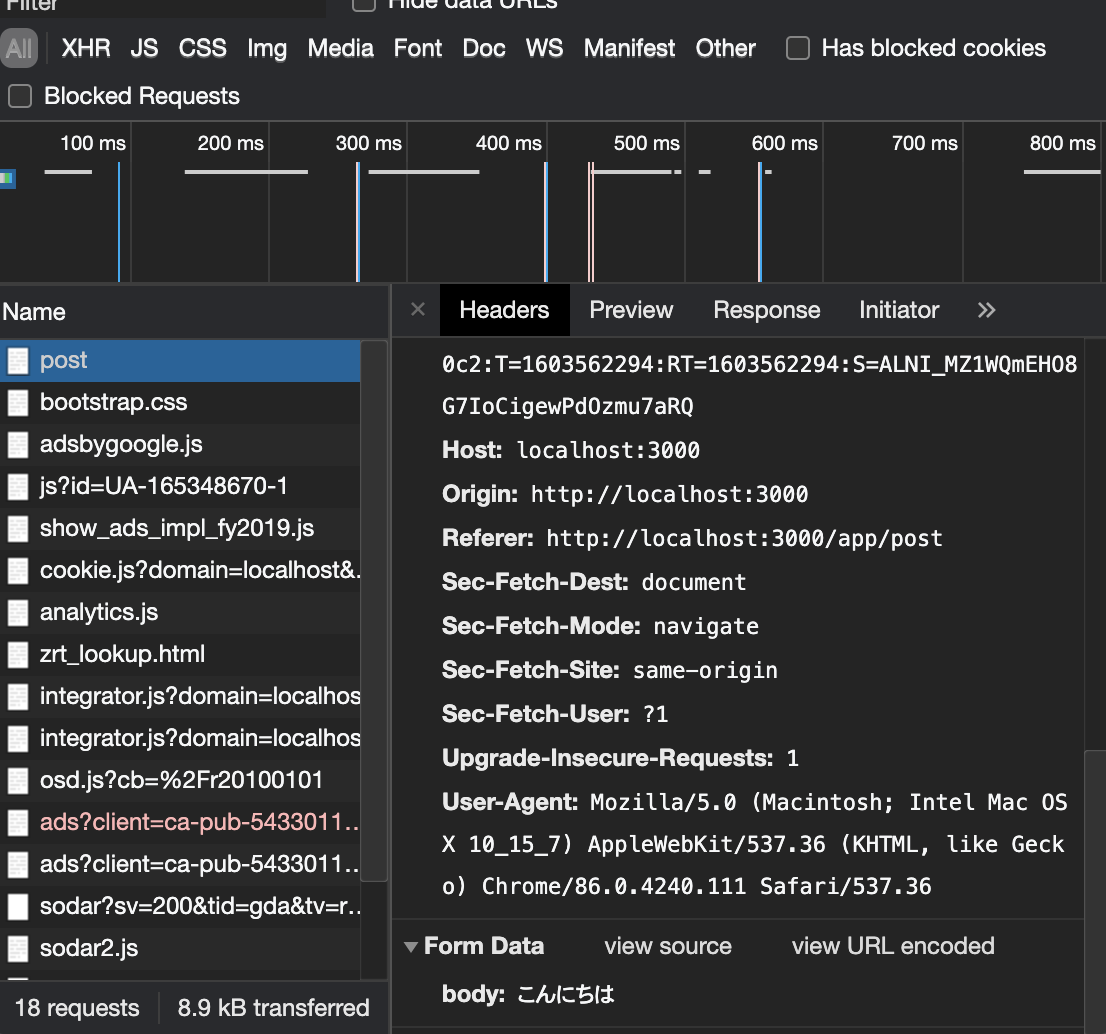
クリックすると拡大できます
Generalのところに表示されるRequestMethodがPOSTになっており、またHeadersタブで表示されたデータの末尾にFormDataという欄が追加され、テキストフォームに入力した値の記載がされていることが確認できます。
Response Header
続いてResponseHeaderの代表的なHeaderパラメータをみてみましょう。
Status Code
Status Codeは当該通信の成功失敗結果を表すものです。100番台、200番台、300番台、400番台、500番台の5種類のグルーピングがされています。
100番台
100番台は処理継続中を表します。ほとんど見かけることはありません。
200番台
200番台はアクセス成功で、正常にWEBページがみれているケースではほとんどが200のStatus Codeを返しています。
300番台
300番台はリダイレクトです。このステータスが出た場合、別のページにアクセスしてくださいということを表します。ブラウザはこのステータスを受け取ると自動的に案内されたページに再アクセスします。再アクセスすることをリダイレクトといいます。
リダイレクトの様子がわかるURLを用意しました。デベロッパーツールを開いた状態で、https://miyau5555.info/app/network/redirect-fromというURLを入力してアクセスしてみてください。
ページが表示された後、ブラウザ上部のURLの末尾が「/redirect-from」ではなく、「/redirect-to」に変わっていることにお気づきでしょうか。「/redirect-from」というページにアクセスすると「/redirect-to」というページにリダイレクトするようにサーバがレスポンスを出したため、ブラウザが自動的に「/redirect-to」にアクセスし直したためです。
デベロッパーツールもみてみましょう。redirect-fromという通信が先頭にありますのでこのHeadersをみてみましょう。302 FoundというStatus Codeになっています。これがリダイレクトを表すStatus Codeです。
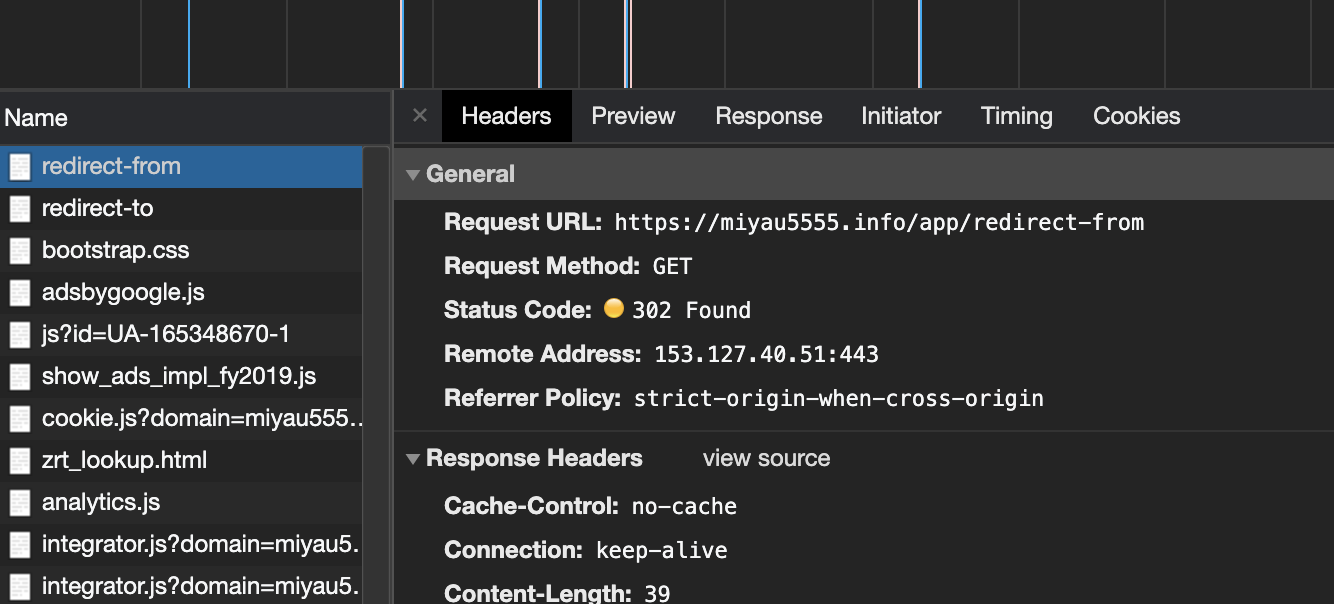
クリックすると拡大できます
なお、ResponseHeadersのところにLocationというパラメータがあり、「/app/network/redirect-to」というリダイレクト先のパスが書かれていることが確認できます。ブラウザは302のステータスコードを受け取った後、Locationというパラメータをみてリダイレクトを実施しています。
400番台
400番台はクライアント側の入力ミスによるエラーを示しています。代表的なものに以下があります。
- 400 Bad Request:入力に何らかの誤りがあったことを表しています。
- 401 Unauthorized:ログイン必須ページにもかかわらず未ログインの状態にアクセスしてしまった時に表示されます。
- 404 Not Found:URL入力間違いなどで存在しないページにアクセスしてしまった時に表示されます。
400番台のエラーがでたときは、ブラウザなどのクライアント側の入力が何らかの間違いがあるケースですので、入力内容を再確認するようにしましょう。
500番台
400番台がクライアントエラー出会ったのに対し、500番台はサーバ側のエラーです。
- 500 Internal Server Error:サーバ側で何らかのトラブルがあったことを表します。
- 503 Service Unavailable:メンテナンス中など、サーバ側が本来のレスポンスデータを提供できない時に表示します。
500番台のエラーコードがあったときは、しばらく時間を待ってアクセスするか、サーバ管理者にお問い合わせをするようにしましょう。
Content-Language
レスポンスデータの言語を表しています。jaの場合は日本語を表し、enのときは英語を表しています。
Content-Type
出力したコンテンツのタイプです。どんなコンテンツなのかを表しています。
レスポンスデータの言語を表しています。
終わりに - さらなる学習をしたい方へ
以上が、WEBサーバにまつわる仕組みでした。今回も概要を解説したのみですので、さらなる学習をしたい方のためのコンテンツを紹介します。
実際にWEBサイト、WEBサーバを作成して学びたい
今回はデベロッパーツールなどを使ってみたものの基本は座学的な内容でした。やはりWEBサイトを実際に公開してみたり、WEBサーバそのものを立ち上げて覚えたい方の方が多いかと思います。
そんな方のために以下の記事を用意してあります。興味がありましたら読んでみてください。
体系的に学びたい
WEBの仕組み関する情報はネットで検索してもたくさんの情報がありますが、体系的に学ぶことができて、辞書として末長く支える書籍として「WEBを支える技術」という本を紹介します。
古い本ですが、WEBエンジニアであれば今でも一読することが奨励される一冊です。私自身も修行時代手に取り、その後も辞書として活用し続けました。もしも興味がありましたら手にとってみてください。
最後まで読んでいただきありがとうございました。WEBの仕組みについて少しでも興味を持っていただければ幸いです。
Photo by Lee Campbell on Unsplash



